
Discover the power of leadership assessment tests and why they matter for your growth. Explore five key reasons that make these tests essential for unlocking your leadership potential.
Discover the power of leadership assessment tests and why they matter for your growth. Explore five key reasons that make these tests essential for unlocking your leadership potential.

The outer coating of the car is damaged by dust, pebbles, bird droppings, and tree sap, but taking care of it is the most important way to maintain the car coating.

Encouraging your child to stay active is simpler than you think. Uncover our key suggestions for coaxing them off the sofa and into the great outdoors.

Further developing your blog’s site improvement (Web optimization) can support your site’s perceivability and, subsequently, its guest numbers.

Planning a last-minute Halloween party can be easy and enjoyable with some creative ideas and a bit of effort. Whether you’re looking to create a spooky atmosphere, set up a fun activity, or serve delicious treats, there are plenty of quick and affordable ways to celebrate this spooky holiday.
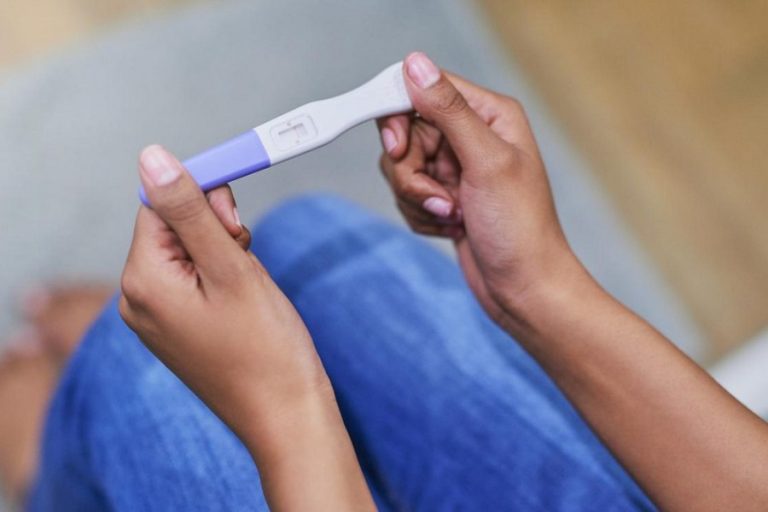
At-home pregnancy tests can be quite accurate, but it’s important to note that not all brands are created equal. The best test for you will depend on which brand you choose and how early in your pregnancy you take the test.

There are some attributes of a latex mattress that makes it a very good choice for back sleepers ensuring comfort.

Enterprises can enjoy improved employee comfort and versatility with partitioning solutions. Businesses can also realize financial gains through office space management. Partitioning allows for unoccupied spaces to be turned into usable workspaces.

You need to check various qualities of a kindergarten school before deciding to enrol your kid in it.

If you want to go for dune bashing and stargazing with your beloved, there are some vital aspects that you should keep in mind.

It is wise to know about different ways to protect your mattress against stains. It is a good idea to hire experts.

Following a workout routine is a good way to start for beginners in a ladies’ gym to build a better fitness level.